Privacy-Handbuch
| File Size | : 76 kB |
| File Type | |
| MIME Type | : application/pdf |
| PDF Version | : 1.5 |
| Linearized | : No |
| Page Count | : 3 |
| Page Mode | : UseOutlines |
| Author | : Max Mustermann |
| Title | : Sinnlose Präsentation für Metadaten Beispiel |
| Creator | : LaTeX with Beamer class |
| Producer | : pdfTeX-1.40.18 |
| Create Date | : 2018:05:08 12:38:21+02:00 |
| Modify Date | : 2018:05:08 12:38:21+02:00 |
| Trapped | : False |
| PTEX Fullbanner | : This is pdfTeX, Version 3.14159265-2.6-1.40.18 (TeX Live 2017/Debian) kpathsea version 6.2.3 |
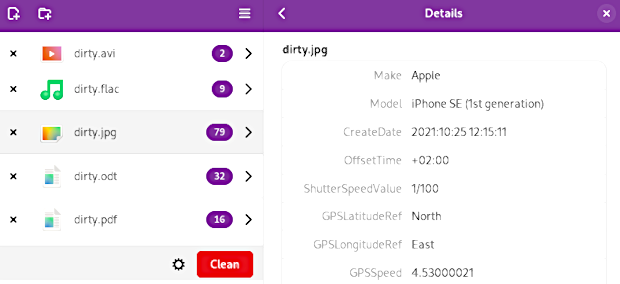
Wenn man PDF Dokumente im Internet veröffentlicht, werden die Metadaten von Suchmaschinen gescannt und in den Index aufgenommen. Wenn man eigene PDF Dokumente in einem anonymen Blog veröffentlichet, könnte man anhand der Metainformationen als Autor deanonymisiert werden.
Die online versendeten PDFs oder Berwerbungsunterlagen werden ebenfalls geprüft:Neben den Metainformation des PDF Dokumentes können auch eingebundene Bilder u.ä. verräterische Metainformationen enthalten. Die Auswertung ist allerding komplizierter.Mein erster Blick bei allen PDF-Bewerbungen und PDF-Dateien von Banken, Versicherungen und Firmen erfolgt stets in die Dateieigenschaften der PDFs. Das ist immer aufschlussreich, oft witzig, manchmal peinlich oder aus Daten- und IT-Sicherheitsblickwinkel bedenklich…
Bei Bewerbungsunterlagen habe ich damit einen wunderbaren Ansatzpunkt für Diskussionen, wenn der Autor eines PDFs z.B. bewerbungsmappe.de oder der Name eines Nicht-Ehepartners oder der bisherige Arbeitgeber ist. Man erkennt sofort…
LaTEX PDFs mit minimalen Metadaten erstellen
Da oben ein LaTEX Dokument als Beispiel genannt wurde ein kleiner Hinweis: LaTEX erstellt PDF Dokumente mit minimalen Metadaten, wenn man das Paket "pdfprivacy" einbindet:
\documentclass[twoside,a4paper,11pt,openany,hyphens]{report}\usepackage{pdfprivacy}
...
Warnhinweis
Es gibt einige Tools, die behaupten, Metadaten aus PDFs mit dem ExifTool entfernen zu können.
Dabei werden eingebette Bilder nicht gereinigt. Außerdem sind die Änderungen reversibel (die alten Daten sind weiterhin im PDF enthalten), wenn das Dokument nicht nachträglich linearisiert wird.
PDF Dokumente säubern (Linux)
Um die verräterischen Metainformationen von eingebundenen Bilder und anderen Medien zu entfernen, öffnet man das Dokument am einfachsten in einem PDF Viewer (z.B. Okular) und druckt die Datei in eine neue PDF Datei "datei-print.pdf".
Dabei werden die Seiten von Ghostscript komplett als neue Bilder gerastert. Als Nebeneffekt werden dabei auch unsichtbare PDF-Wanzen entfernt.
- Die restlichen Metainformationen kann man dann mit den Tools "exiftool" und "qpdf" entfernen. Beide Programme kann man mit dem bevorzugten Paketmanager installieren:
Debian: > sudo apt install libimage-exiftool-perl qpdf
Fedora: > sudo dnf install perl-Image-ExifTool qpdf Zuerst werden alle Metadaten mit "exiftool" auf leere Werte gesetzt, dann wird das PDF Dokument mit "qpdf" behandelt, damit die reversiblen Rückstände verschwinden: > exiftool -all:all= datei-print.pdf
Warning: [minor] ExifTool PDF edits are reversible. Deleted tags may be recovered!
1 image files update
> qpdf --linearize datei-print.pdf datei-clean.pdf
> rm datei-print.pdf"exiftool" arbeitet in-place und modiziert die Input Datei direkt, "qpdf" liest eine Input Datei und schreibt das Ergebnis in eine neue Output Datei.
Mit folgendem Kommando kann man dann abschließend die Metadaten prüfen: > exiftool -all:all datei-clean.pdf
....
MIME Type : application/pdf
PDF Version : 1.5
Linearized : Yes
Page Mode : UseOutlines
Page Count : 4 - Man könnte sich auch ein kleines Script schreiben, um den Aufruf von exiftool und qpdf zu vereinfachen. Das folgende Mini-Script pdf-meta-clean.sh (mit ein bisschen Fehlerbehandlung) wird mit den Namen der zu reinigenden PDF-Dateien aufgerufen. Es macht seine Arbeit und danach sind die Metadaten weg. (Es wird kein Backup der originalen Dateien behalten!)
#!/bin/bash
if [ -z `which exiftool` ]; then
echo "FEHLER: Das Programm exiftool ist nicht installiert!"
exit 1
fi
if [ -z `which qpdf` ]; then
echo "FEHLER: Das Programm qpdf ist nicht installiert!"
exit 1
fi
if [ -z "$1" ]; then
echo "Usage: `basename $0` <Dateiname>"
exit 1
fi
until [ -z "$1" ]; do
if [ ! -f "$1" ]; then
echo "FEHLER Die Datei $1 ist nicht vorhanden!"
shift
continue
fi
FILETYPE=`mimetype -b "$1"`
if [ $FILETYPE != "application/pdf" ]; then
echo "FEHLER: Datei $1 ist keine PDF Datei!"
shift
continue
fi
if [ ! -w "$1" ]; then
echo "FEHLER Die PDF Datei $1 kann nicht modifiziert werden!"
shift
continue
fi
exiftool -all:all= "$1" > /dev/null >> /dev/null
TFILE=`mktemp`
cp "$1" "$TFILE"
qpdf --linearize "$TFILE" "$1" > /dev/null
rm "$TFILE"
echo "OK: Metadaten von Datei "${1}" entfernt."
shift
done
exit 0 Nach dem Download wird das Script nach /usr/local/bin kopiert und als ausführbar markiert: > sudo cp Download/pdf-meta-clean.sh /usr/local/bin/pdf-meta-clean
> sudo chmod +x /usr/local/bin/pdf-meta-clean Dann kann man folgendes Kommado aufrufen, um mehrere PDF-Dateien zu reinigen: > pdf-meta-clean *.pdf
PDF-Dokumente säubern mit MAT2 (Linux)
MAT2 (Metadata Anonymisation Toolkit 2) ist ein Kommandozeilentool für Linux, das Metadaten von vielen Bild-, Audio-, Video- und Officeformaten sowie PDFs entfernen kann. Für PDFs werden die oben genannten Einzelschritte in einem Kommando zusammengefasst ausführt. Ein PDF Dokument wird mit der Cairo Bibliothek virtuell "gedruckt" und dann werden alle Metadaten entfernt.
Pakete gibt es für Debian basierte Distributionen, OpenMandrive und Void Linux (wobei Debian stable eine veraltete Version enthält, die man durch eine aktuellere Version aus den Backports ersetzen kann). In der Tor Live-DVD TAILS ist MAT2 enthalten. Ubuntus können es wie folgt nutzen:
> sudo apt install mat2> mat2 --inplace <Datei> (ohne Backup der org. Datei bereinigen)
Mit dem Metadaten Cleaner gibt es ein MAT2 GUI als Flatpack für Mäuschenschubser für alle Linux Distributionen, das neben MAT2 auch alle benötigten Bibliotheken und Tools mitbringt.
PDF-Dokumente säubern (QubesOS)
QubesOS hat einen eingebauten Konverter für PDF-Dateien, den man im Dateimanager mit einem Rechtsklick auf ein PDF Dokument aufrufen kann: "Convert to trusted PDF"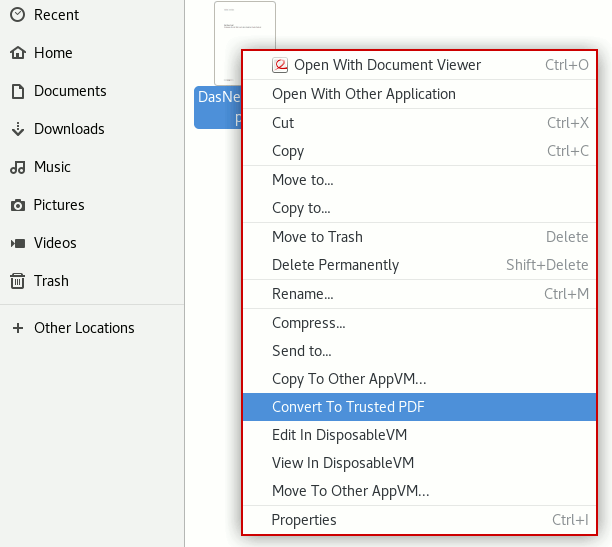
Dangerzone (Windows, MacOS, Linux)
Dangerzone ist vom QubesOS PDF Konverter inspiriert und eine Umsetzung dieses Konzeptes für Windows, MacOS und verschiedene Linux Distributionen.
Ein (möglicherweise bösartiges) PDF- oder Office-Dokument wird in einer virtuellen Wegwerf-Umgebung (Docker) virtuell gedruckt und das Ergebnis neu zusammengesetzt. Dabei werden neben allen Bösartigkeiten auch die ursprünglichen Metadaten aus dem Dokument entfernt.
PDF-Dokumente säubern (Windows)
Auch als Windows Nutzer kann man ein PDF Dokument zuerst in eine neues PDF Dokument drucken, um die Metainformationen von eingebetteten Bildern und Medien zu entfernen. Dafür braucht man einen PDF-Drucker. Dieser Drucker wird z.B. vom PDF Creator von PDF24.org bereitgestellt. Nach der Installation steht der PDF-Drucker zur Verfügung.
Um die restlichen Metadaten zu entfernen gibt es z.B. den Hexonic PDF Metadaten Editor.